AWS Lake Formation makes it easy to create, protect, and manage data lakes. Make a note of the Amazon Simple Storage Service (Amazon S3) bucket and where the data lake is located. Manage the data flow of collecting, cleaning, transforming, and organizing raw data. Create and manage a data catalog containing metadata about data sources and data in the data lake. Use the commit/withdraw model to define fine-grained data access, metadata, and data access standards.
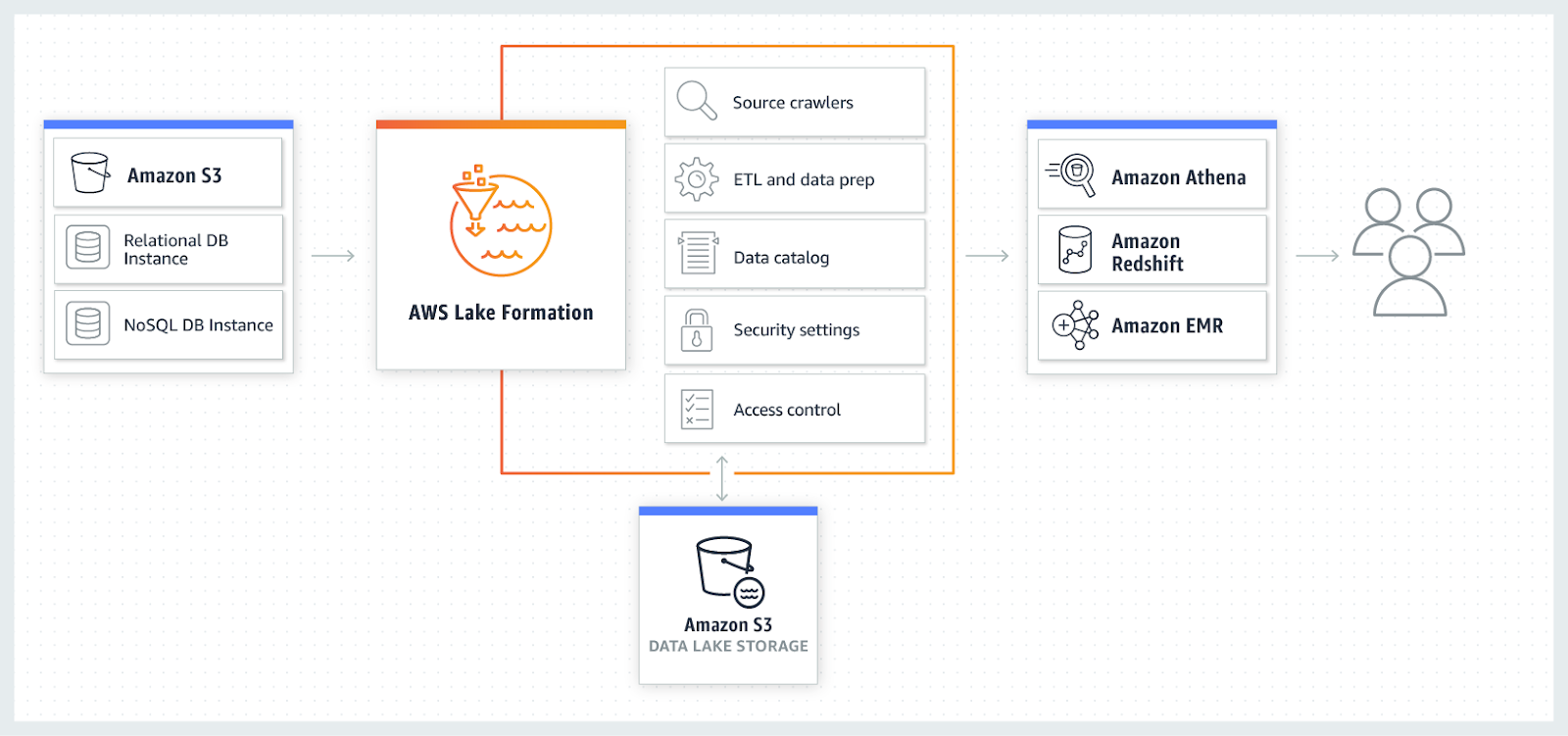
The following figure shows how to load and protect data in Lake Formation. As shown in the figure, Lake Formation manages the AWS Glue crawler, AWS Glue ETL process, data catalog, security settings, and access control. Once the data is safely stored in the data lake, users can access it through the analysis services of their choice, including Amazon Athena, Amazon Redshift, and Amazon EMR.
Below are some of the essential terms you will come across in this guide.
The data lake is your persistent data stored in Amazon S3 and managed by Lake Formation using the data catalog. For an Amazon S3 path to be in a data lake, it must be registered with Lake Formation. Lake Formation provides granular and secure access to data through a new grant/revocation model that extends AWS Identity and Access Management (IAM) policies. Analysts and data scientists can use the entire portfolio of AWS analytics and machine learning services such as Amazon Athena to access data. Customized Lake Formation security policies help ensure that users can only access the data they have access to.
The project is a data management model that easily inserts data into the data lake. Lake Formation provides multiple projects, each used for predefined source types, such as relational databases or AWS CloudTrail logs. You can create workflows from projects.
Workflows are made up of AWS Glue crawlers, processes, and triggers that you create to coordinate data uploads and updates. Diagrams take a data source, destination, and schedule as input to customize a workflow. A workflow is a container for several AWS Glue processes, crawlers, and related triggers.
You create a workflow in Lake Formation, and it runs on AWS Glue. Lake Formation can track the status of a workflow as a whole. When you define a workflow, you choose the project based on it.
You can then run the workflow on-demand or on a schedule. The workflow created in Lake Formation is displayed as a forward acyclic graph (DAG) in the AWS Glue console. Using DAG, you can track the progress of the workflow and perform troubleshooting.
Data Lake
The data directory is your permanent metadata repository. It is a managed service that lets you store, annotate, and exchange metadata in the AWS Cloud, just like Apache Hive Metadata Store. It provides a single repository where disparate systems can store and find metadata to track data across disparate data stores and then use that metadata to query and transform the data.
Data Access
Lake Formation uses the AWS Glue Data Catalog to store data lakes, data sources, transformations, and destinations.
Metadata about data sources and destinations are presented in databases and tables. The table stores schematic information, location information, etc. A database is a collection of tables.
Lake Formation provides a hierarchy of permissions to control access to databases and tables in the information catalog.
Reference data refers to the original or data in the data lake pointed to by the data catalog table.
A principal is an AWS Identity and Access Management (IAM) user or role or an Active Directory user. A data lake administrator is an entity that can grant any entity (including itself) any permissions to any data catalog resource or data location. Make the data lake administrator the first user of the data catalog. This user can then grant more granular resource permissions to other objects.
Administrative IAM users, users with a managed AWS AdministratorAccess policy, do not automatically become Data Lake Administrators. For example, they cannot grant Lake Formation permissions on catalog objects unless permission is given. However, they can use the console or the Lake Formation API to designate themselves as data lake administrators.
For more information about the capabilities of the Data Lake Administrator, see Implicit Lake Formation Permissions. For details on making a user the data lake administrator, see Create a data lake administrator. AWS Lake Formation leverages the interaction of multiple components to create and manage a data lake.
Lake Formation Components
The Lake Formation console is used to define and execute a data lake and grant and revoke Lake Formation permissions.
You can use the items in the console to discover, clean, transform, and import data. You can also enable or disable console access for individual
Lake Formation API and Command Line Interface
The Lake Formation API mainly focuses on managing Lake Formation permissions, while the AWS Glue API provides data catalog APIs and hosting infrastructure for defining, scheduling, and executing data ETL operations. AWS Glue is used for job management and crawlers to transform data using AWS Glue transformations.
IAM to provide authorization policies to Lake Formation principals. The Lake Formation authorization model supports the IAM authorization model for securing the data lake.